论文学习:Lip Reading-Based User Authentication Through Acoustic Sensing on Smartphones
文章题目:Lip Reading-Based User Authentication Through Acoustic Sensing on Smartphones
来源:IEEE/ACM Transactions on Networking 2019
文章概述
为了防止用户隐私泄露,越来越多的移动设备采用基于生物特征的身份验证方法(例如指纹,面部识别,声纹身份验证等)来增强隐私保护。但是,这些方法很容易受到重放攻击。尽管最新的解决方案利用活性验证来抵御重放攻击,但现有方法对周围环境(例如环境光和周围的噪声)很敏感。为此,本文探索了一种基于用户嘴唇运动的方式来进行活性验证,且该方法对周围的环境鲁棒性很高。在本文中提出了一种基于唇读的用户身份验证系统LipPass,通过智能手机上的声音感应提取用户说话时嘴巴的独特行为特征,以进行用户身份验证。本文首先调查,智能手机上的音频组件可以通过分析用户脸部反射的声音信号来描绘用户嘴巴的运动。由于每个人都表现出独特的说话行为——比如嘴唇的凸起和闭合、舌头的伸展和收缩,以及下颌的角度变化等——这创造了一个独一无二的多普勒效应轮廓,这轮廓能够用手机检测到。为了表征嘴的运动,本文使用一种深度学习算法,在用户说话时从用户的多普勒轮廓中提取显著的特征。接下来,应用一种基于二叉树的方法来辨别是新用户的轮廓还是以前注册的用户的轮廓,这也有助于在合法用户身份和欺骗者之间做出辨别。通 过在四个实际环境中进行的涉及48位志愿者的广泛实验,LipPass可以实现90.2%的用户识别准确度和93.1%的欺骗者检测准确度。
系统框架
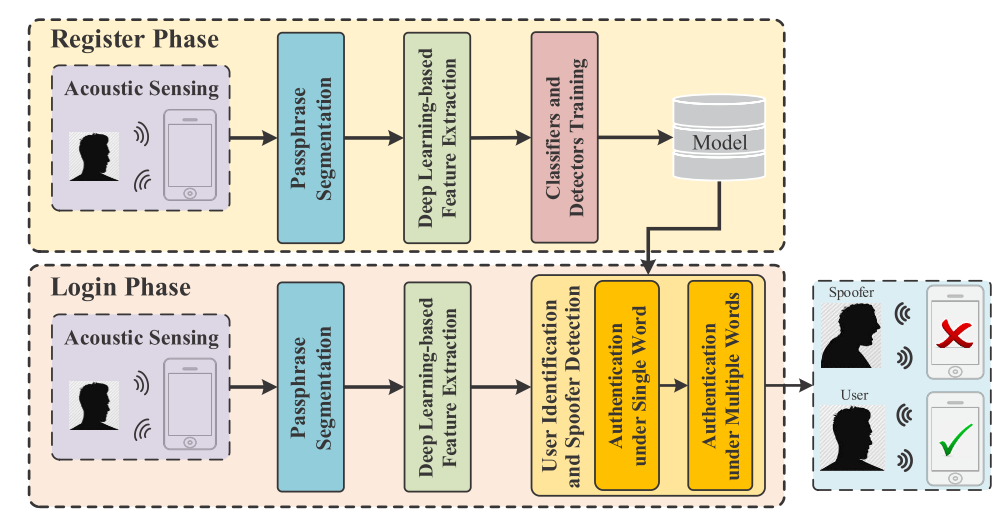
处理流程
注册阶段
当用户对着手机念与预定义好的短语时,控制手机的扬声器发送$f_0=20kHz$的高频声波信号,然后接受反射回来的信号,将其进行FFT后,对连续的两个时间片之间做差运算,从而得到用户的原始数据
Doppler Profile,G(t)。由于用户说出的短语包含多个单词,且每个单词之间往往都有短暂的停顿(约300ms),因此需要将采集到的G(t)分割成单个单词的多个小片段,可以通过设置一个阈值来实现,而且也能顺便去除环境噪音。
由于直接将分割得到的包含单个单词
Doppler Profile作为特征的话,该特征维度过高,会引起复杂度过高,过拟合等现象。因此LipPass采用基于DNN的DAE(Denoising Autoencoder)来对G(t)进行特征抽取。使用Denoising,对输入数据的部分神经元进行随机失活增加该模型提取特征的鲁棒性。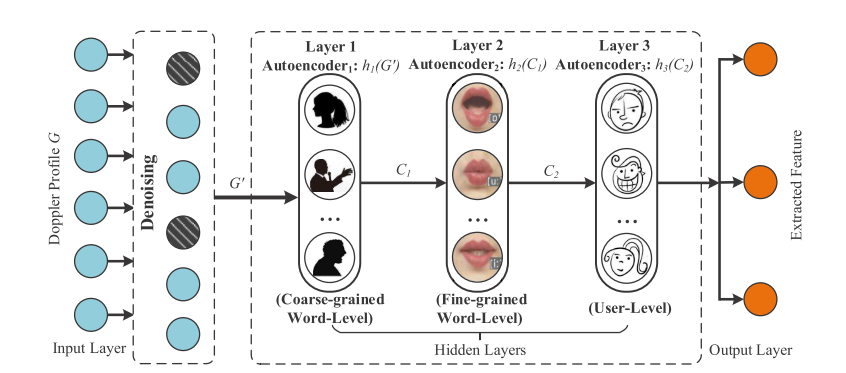
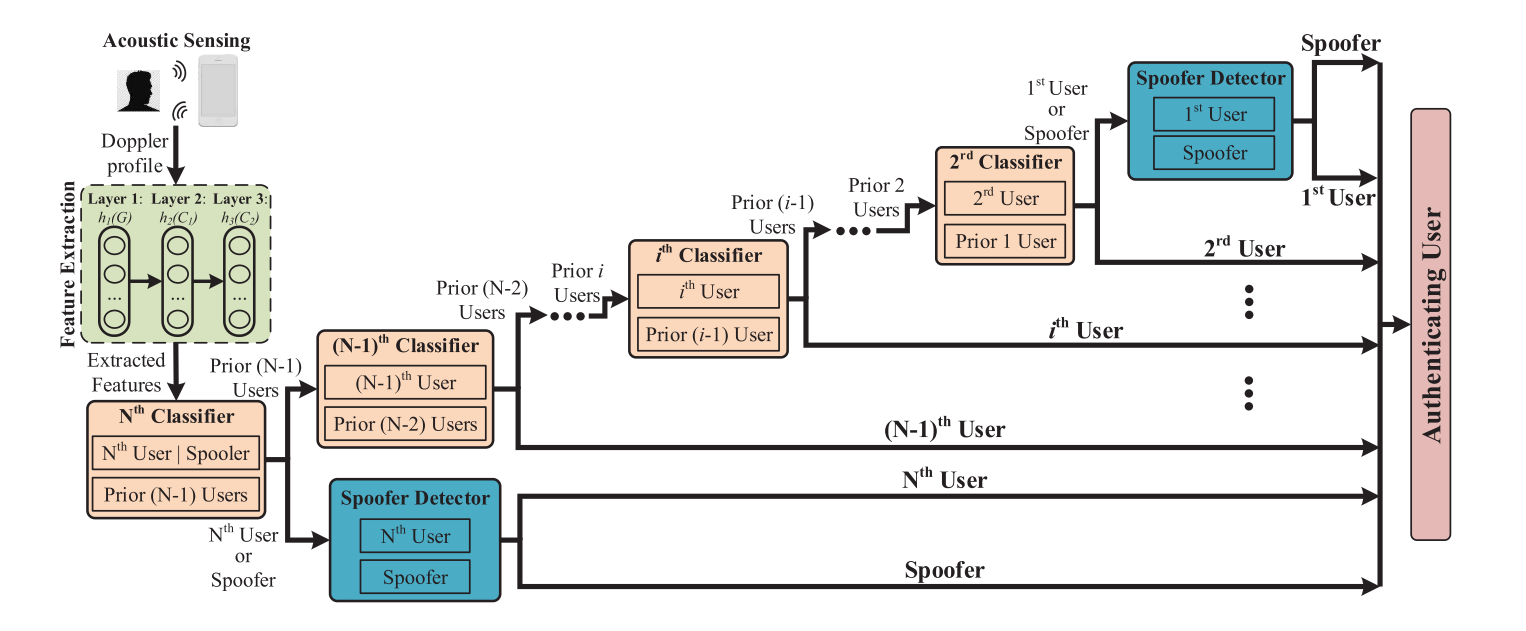
以从单个单词上提取到的特征数据为训练数据,使用SVDD进行分类器训练,得到单用户的伪装者检测器(判断是否为用户or伪装者)。为了支持多用户使用,可以选择训练一个多分类器,但这种方法由于每当一个新用户进行注册,那么整体模型就要进行重新训练(加入了一个新的分类),这会导致极大的计算开销,从而使用户在注册时等待时间过长。为了避免这一点,LipPass使用了一个基于二叉树的分类框架,对每个注册用户都训练一个基于SVM的二分类器。例如当第n个用户进行注册时,将第n个用户的特征与前n-1个用户的特征作为两类训练样本进行SVM训练,并同时为每个用户使用SVDD训练一个伪装者检测器,这样就可以判别当该用户是前n-1个用户还是第n个用户还是伪装者了。
登陆阶段
- 在登陆阶段,用户需要向LipPass说出预定义好的的短语,LipPass同样控制手机的扬声器发送$f_0=20kHz$的高频声波信号,然后接受反射回来的信号,将其进行FFT后,对连续的两个时间片之间做差运算,从而得到用户的输入数据
Doppler Profile,G(t)。 - 同注册阶段一样,对输入数据进行词语分割,得到单个单词的数据。
- 同注册阶段一样,使用DNN模型对登录用户的输入数据进行特征提取,得到单个单词的特征。
- 为了加强LipPass对于检测用户,识别伪装者的能力,LipPass使用了基于权重投票系统的判断策略,即对于用户说出的每个单词特征都使用上述的二叉树分类框架进行判断,将判断的结果加权后作为最后的检测结果。以每个单词所含的音节数为权值,音节数越多,该单词判断结果的权值越高,对于最终检测结果的影响就越大。最后根据投票策略计算出的结果给出登录用户最终身份检测结果。
系统优化
Eliminating Multi-path Interferences from Body Movements
由于当用户在对着手机说话时,其身体可能也在运动,因此也会产生多普勒效应。为了提升LipPass性能,需要将这些信号去除。由身体运动引起的多普勒效应其频率改变往往在[50,200]Hz,而由嘴唇引起的多普勒效应其频率改变往往在[-40,40]Hz,因此可以使用巴特沃斯(butterworth)低通滤波器对输入信号进行过滤,从而得到仅包含由嘴唇运动引起的多普勒效应信号。
Removing Multi-path Interferences from Static Objects
由于发射的声信号可能会反射到周围其他物体上,因此需要对这些信号进行去除。因为用户嘴部离手机的距离(基本小于10cm)远小于手机离周围物体的距离,因此由嘴唇反射回的信号强度肯定大于由周围物体反射回的信号强度,所以可以设置一个阈值将低于阈值强度的信号过滤掉即可。
问题
- Autoencoder模型结构,数据集?
- 为什么要对说话短语进行分词?
- 实现上有点困难,有没有源代码
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!