论文学习:Practical Adversarial Attacks Against Speaker Recognition Systems
文章题目:Practical Adversarial Attacks Against Speaker Recognition Systems
来源:ACM HotMobile 2020
文章概述
对基于X-vector的multi-class speaker recognition system(其实就是一个闭集多分类模型,speaker identificaiton)进行adversarial example attacks,即对输入音频加入人类察觉不到的小扰动使得speaker recognition system分类出错。具体包括两种攻击类型:untargeted attack and targeted attack。并且加在generate adversarial example时加入了estimated RIR(room impulse response),模拟在真实场景下的各种因素(multi-path effect, noise etc.)。在VCTK数据集上进行digital attack和practical attack,每种场景下都评估上述两种攻击类型的表现。98% digital untargeted attack success rate, 50% practical targeted attack success rate。
系统框架
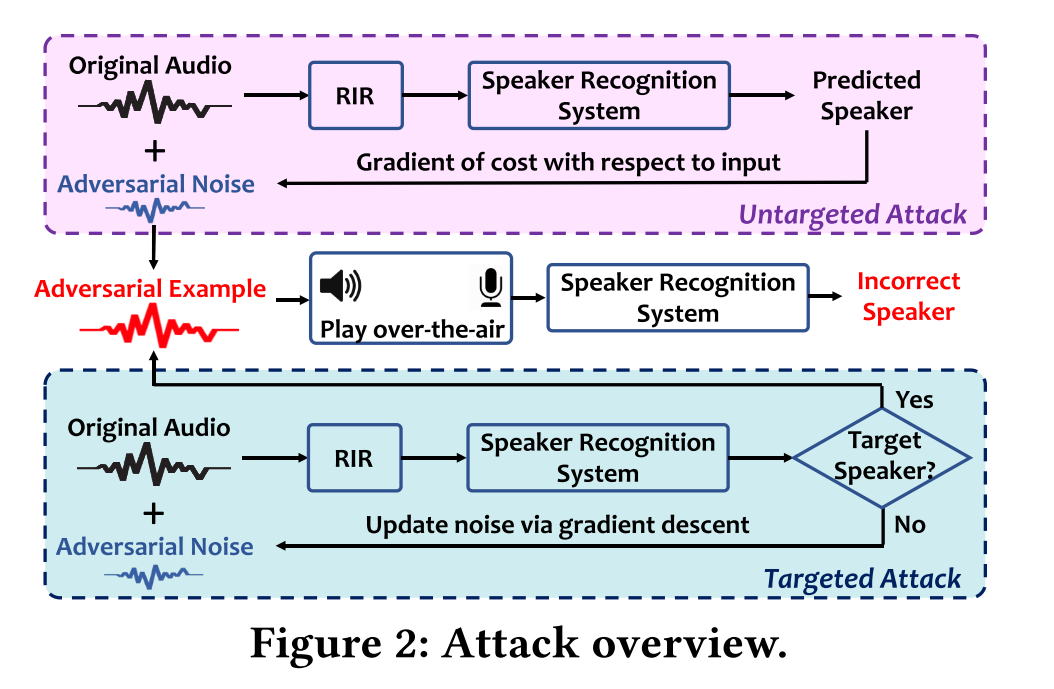
处理流程
Room impulse Response Estimation
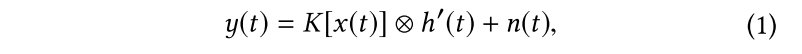
其中,$
y\left( t \right)
$是麦克风记录音频样本,$
x\left( t \right)
$是扬声器发出的音频样本,$
K\left[ \right]
$ is the N-th order discrete-time Volterra kernel to represent a nonlinear memoryless system,$
h’\left( t \right)
$ is an impulse response characterizing linear distortions (i.e., delays and attenuations),$
\bigotimes
$是卷积操作,$
n\left( t \right)
$是与输入音频无关的环境噪声。
实际情况下一般简化考虑为:
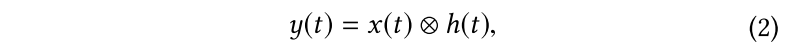
其中$
h\left( t \right)
$为RIR(Room Iimpulse Response),是一个能够综合表示线性和非线性的因素的脉冲响应。
文章通过preliminary experiment测量出不同场景下的estimated RIR,具体如下:
1.使用扬声器发射一个刺激信号$
x_e\left( t \right)
$,具体可表示如下:
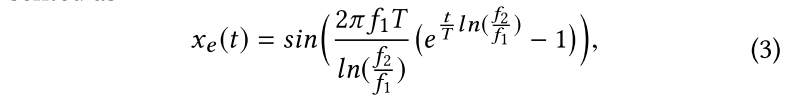
2.使用麦克风记录音频信号,通过卷积操作得到estimated RIR, $
h\left( t \right)
$,具体如下:
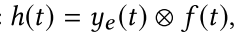
其中$
f\left( t \right)
$由$
x_e\left( t \right)
$进行time-reversal得到
通过实验证明了这种preliminary experiment的有效性,在后续攻击评估中都使用了这种方法预先测量出estimated RIR

Untargeted Attack Example
untargeted attack即使得speaker recognition system分类错误就行,制造这种example只需对输入样本加上一个扰动$
\delta
$即可:
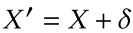
由于是untargeted attack,因此扰动$
\delta
$可以直接利用DNN模型的局部线性特性,使用FGSM(fast gradient sign method)生成,即对每个输入样本计算(一次计算生成):
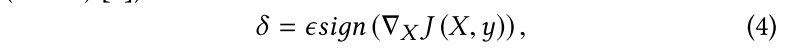
具体到本文攻击的x-vector多说话人分类模型,因此loss使用cross-entropy,adversarial example可表示为:
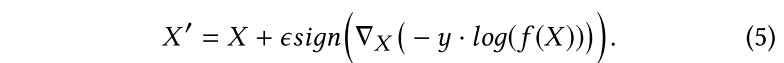
对应的,在真实场景中进行attack的example,加入estiamted RIR即可:
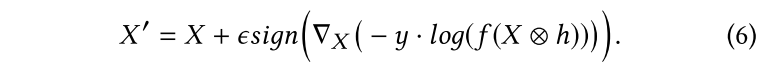
Targeted Attack Example
由于是targeted attack,需要让speaker recognition system将adversarial example分类为攻击者指定的目标$
y_t
$。因此需要解决一个optimization problem:
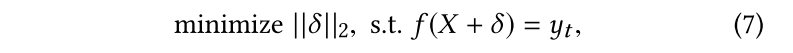
上式可简化为:
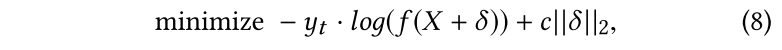
因此需要对每个样本进行梯度下降(迭代生成)得到optimal $
\delta *
$,然后对原始样本加上扰动即可
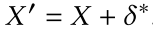
类似的,如果要生成在真实场景下的adversarial example,考虑estimated RIR即可:
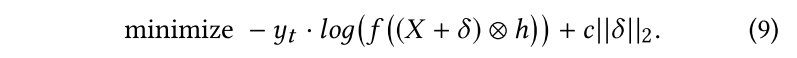
实验评估
数据集和Baseline Model
使用VCTK数据集,对x-vector多说话人分类speaker recognition systemt进行adversarial example attack evaluation
Metrics
- Speaker Recognition Accuracy
- Attack Success Rate
- Distortion Metric:评估perturbation相对原始音频的幅值占比,越大代表扰动perturbation越明显,越容易被发觉
实验结果
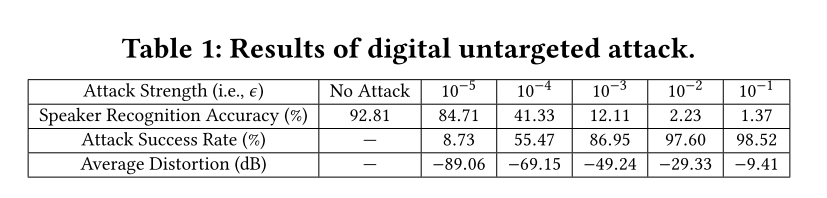
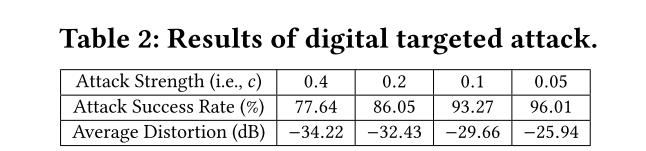
Evaluation of Digital Attacks
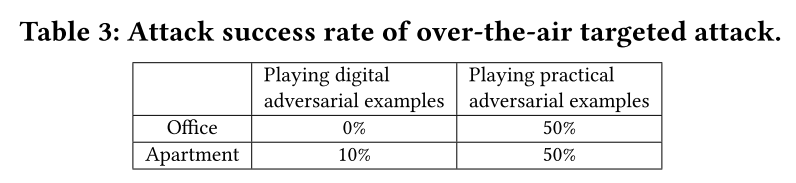
Evaluation of Practical Attacks

对于untargeted attack,由于various environmental interferences (e.g., multipath, ambient noises),导致x-vector based speaker recognition mis-classified all samples. 因此attack success ratio是100%
问题
white-box setting
has complete knowledge to the speaker recognition model,需要Practical Black-box Attack,比如现在商用的speaker recognition system(e.g. Microsoft Azure)是不公开model的
可能的解决方案
gradient-free optimization algorithms (e.g., genetic algorithm)
training a substitute model.
estimated RIR:
通过preliminary experiment来estimating RIR,可能在某些室内场景中是不可行的或者在室外环境中是很难实现的
可能的解决方案
- room simulators to approximate the actual RIR
- RIR augmentation techniques:direction-to-reverberant ratio (DRR)
Bypassing Liveness Detection
防守方可以加入liveness detection即可抵抗本文的攻击方法
可能的解决方案
- 设计一种audio-agnostic universal perturbation,与输入音频样本无关,当活体输入语音时,注入这种perturbation从而绕过liveness detection
文章的Practical attack evaluation
由于文章中使用的Speaker recognition system是Kaldi Pre-trained,因此并不具备Robust ablilty to environmental interferences,因此得到的实验结果其实也是不可靠的。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!