Adversarial Defense for Automatic Speaker Verification by Cascaded Self-Supervised Learning Models
文章题目:Adversarial Defense for Automatic Speaker Verification by Cascaded Self-Supervised Learning Models
一作:Haibin Wu
机构:National Taiwan University
来源:ICASSP 2021 - 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)
Contribution
We are among the first to propose the self-supervised learning based models for adversarial defense on ASV systems. We begin with applying hand-crafted filters including Gaussian, mean and median filters, to counter adversarial attacks for ASV. Experimental results demonstrate that our proposed method achieves effective defense performance and successfully counter adversarial attacks in both scenarios where attackers are aware or unaware of self-supervised learning models.
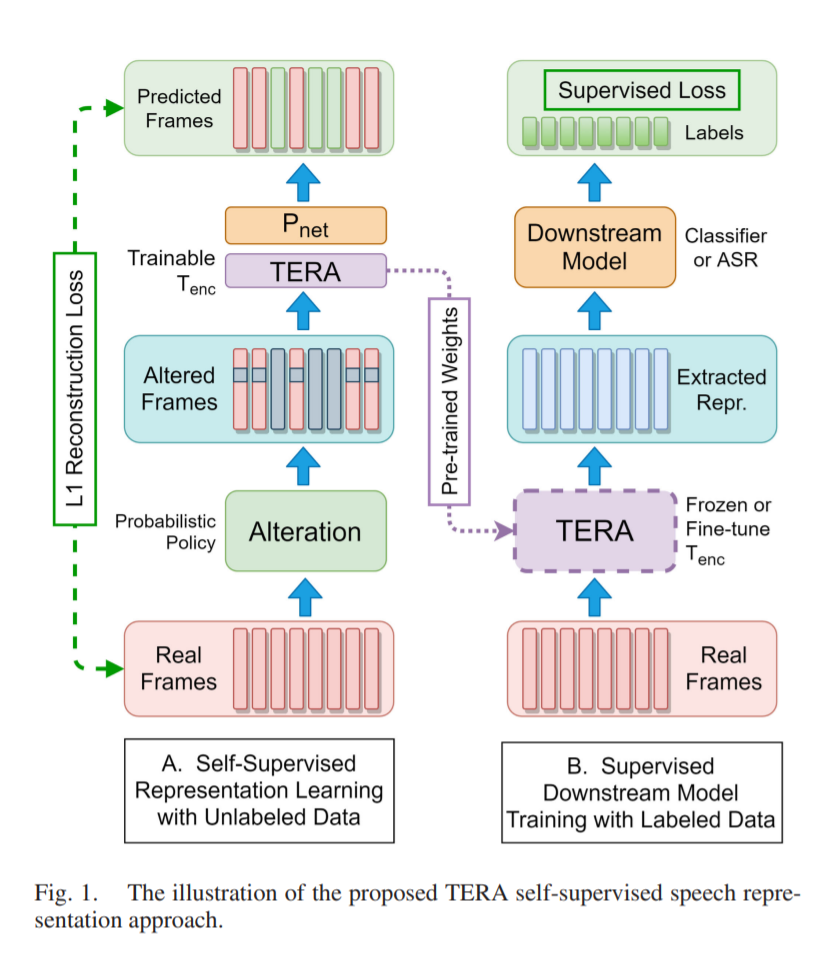
使用自监督学习训练了一个deep filter,即TERA。通过级联多个TERA放在任意ASV前面,对输入进行purify,denoise。并且该filter是attack-agnostic,不需要retrain整个ASV model。
System Design
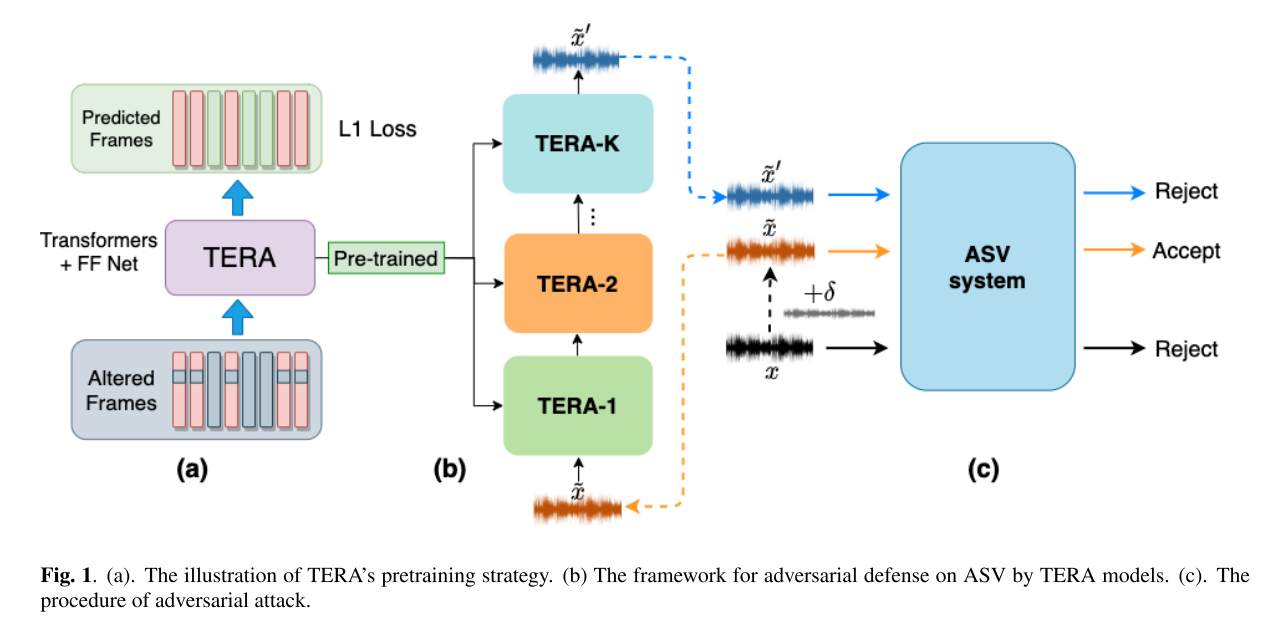
Threat Model
white-box
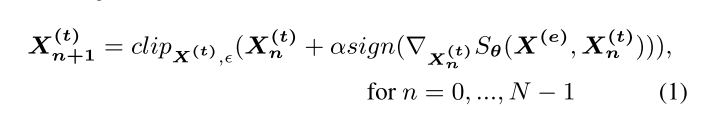
- Adversaries are unaware of TERA
- Adversaries are aware of TERA
Evaluation
ASV performance with genuine and adversarial inputs
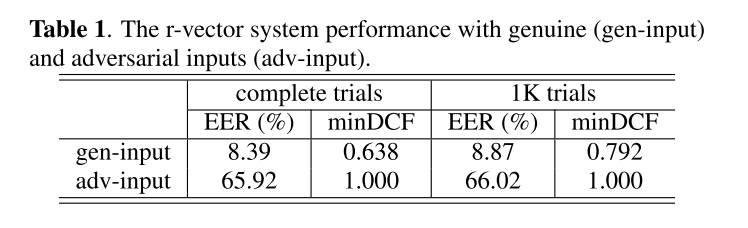
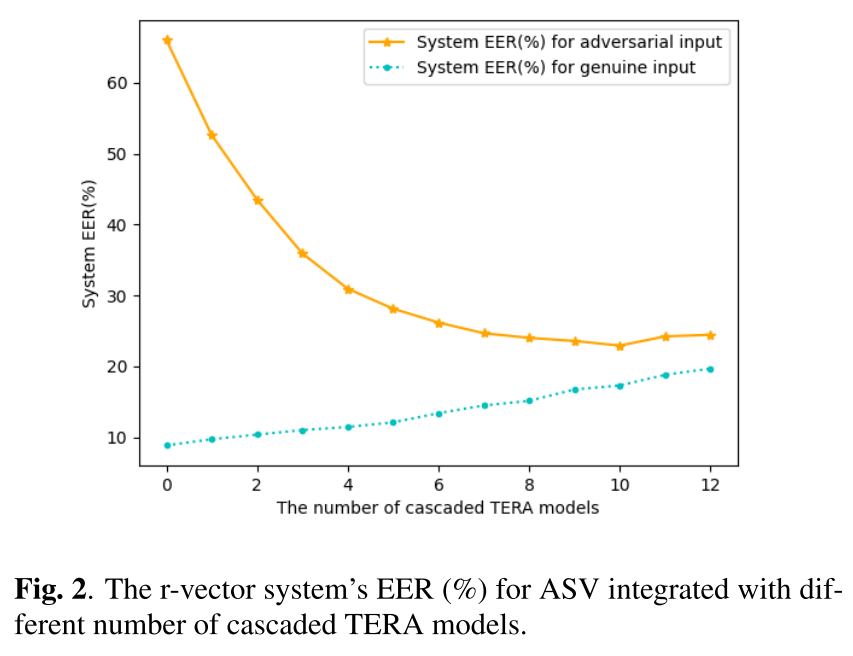
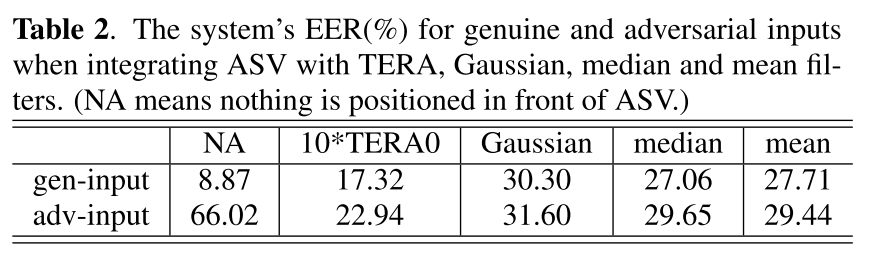
Adversaries are unaware of TERA
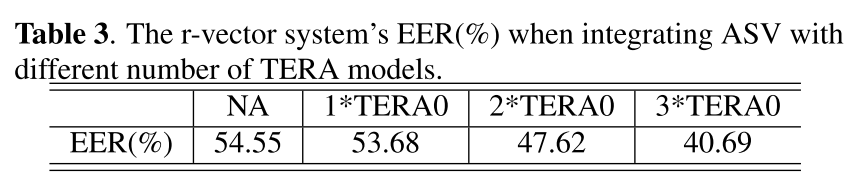
Adversaries are aware of TERA
Problem
- 至少得级联10个TERA才能将adversarial input的EER降低到23%以下,这仍然是个较低的识别效果,而且10xTERA对genuine input的EER也大幅提升到17.32%,这也会极大影响正常用户使用
- 对于aware of TERA attacker的evaluation,结果没有实际意义,因为在生成adversarial example时只考虑1层TERA,防御时却不停叠加TERA,这对于adversary来讲不是完全white-box
- 没有考虑black-box attacker
- 考虑下speaker identification场景?