Dompteur: Taming Audio Adversarial Examples
文章题目:Dompteur: Taming Audio Adversarial Examples
一作:Thorsten Eisenhofer
机构:Ruhr University Bochum
来源:30th USENIX Security Symposium, USENIX Security 2021, August 11-13, 2021
链接:https://www.usenix.org/conference/usenixsecurity21/presentation/eisenhofer
Introduction
Motivation
- Instead of preventing all adversarial examples, we accept the presence of some, but we want them to be audibly changed.
- human auditory system
- Psychoacoustic Modeling
Contribution
- Constructing an Augmented ASR. We utilize our key insights to bring ASR systems in better alignment with human expectations and demonstrate that traditional ASR systems indeed utilize non-audible signals that are not recognizable by humans.通过实验证明现有的ASR利用了人类不可听的一些音频信息来提升performance。对现有ASR做一些修改,增强对输入的过滤,使其更符合人类听觉系统,在此基础上再进行speech recognition。
- Evaluation Against Adaptive Attacker. We construct a realistic scenario where the attacker can adapt to the augmented system. We show that we successfully force the attacker into the audible range, causing an average of 24.33 dB added noise to the adversarial examples. We could not find adversarial examples when applying very aggressive filtering; however, this causes a drop in the benign performance.通过Psychoacoustic Modeling和band-pass filter使得修改过后的ASR更加符合人类听觉系统,更加专注于信号中可听部分。因此面对这种增强后的ASR,以往的AE需要将其perturbation的强度加到足够大,才能不被filter,然而这会导致这种perturbation被人类感知到。因此就算有AE能成功miss lead ASR,但这个AE是十分noisy的,失去了很多实际意义。
Background
Psychoacoustic Modeling
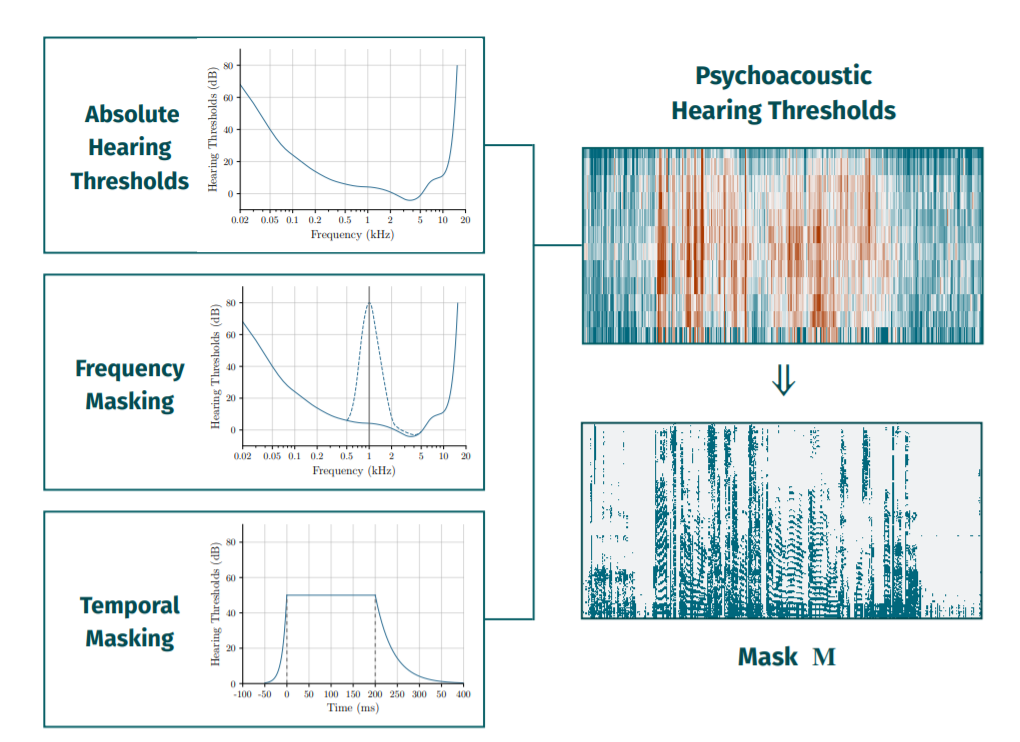
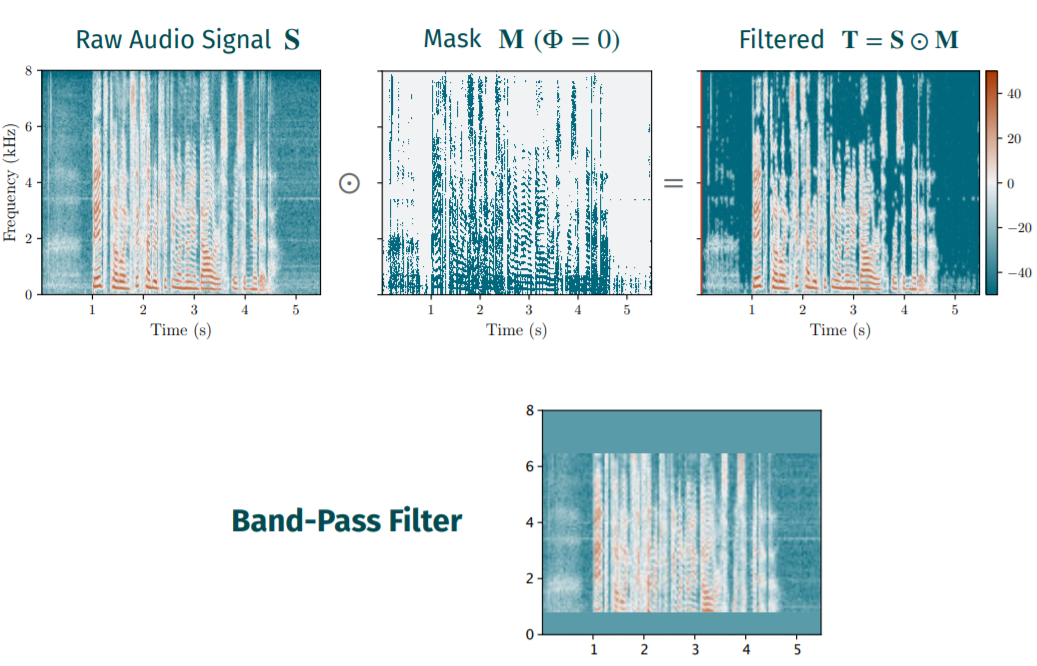
就相当于是一个filter,$\varPhi$可以控制filter strength。
具体过滤规则如下:
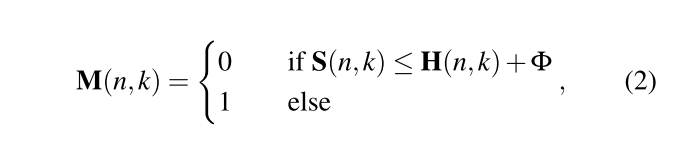
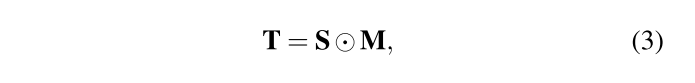
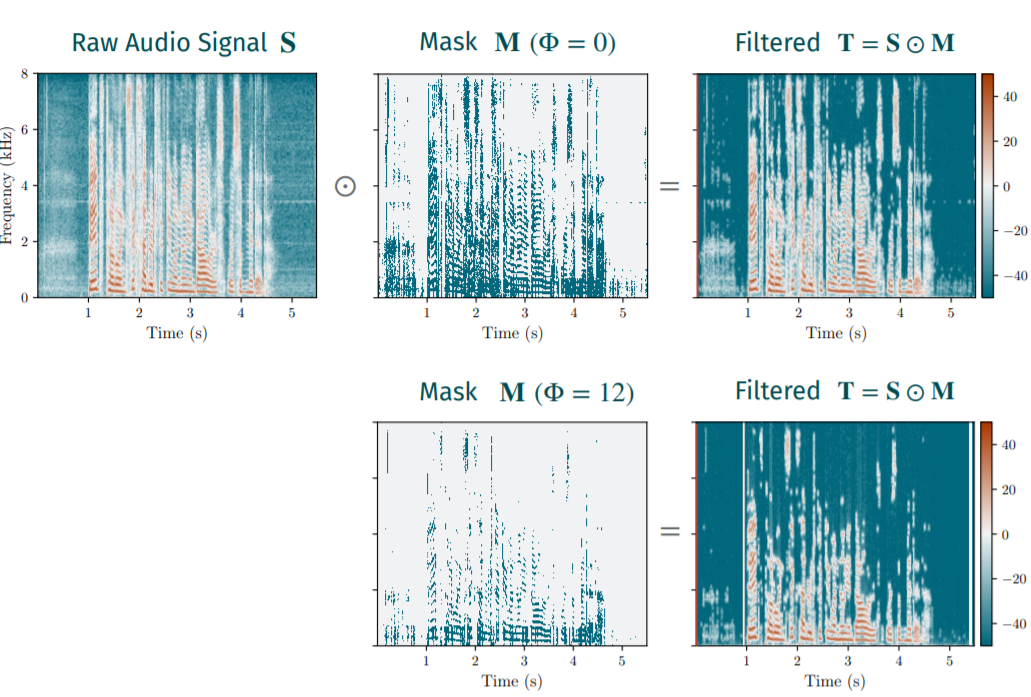
此外本文除了使用Psychoacoustic model进行一次过滤外,还考虑到人耳可听频率范围在基本在300-5000Hz,因此还额外加了一个band-pass filter,只保留200-7000Hz的信息
System Design
Dompteur
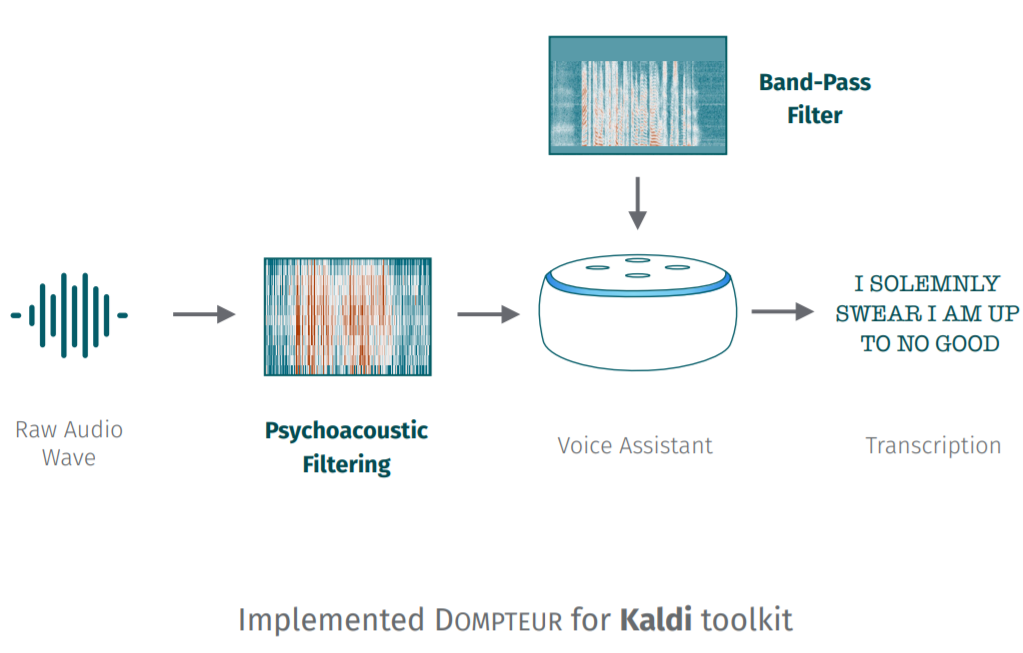
该文设计的dompteur,其实就是在原有的kaldi ASR的preprocess阶段多了两个filter:Pyschoacoustic filter and Band-Pass filter
Threat Model
targeted attack,也是white-box的,adversary可以将Pyschoacoustic filter and Band-Pass filter考虑进optimization中进行gradient descent
Evaluation
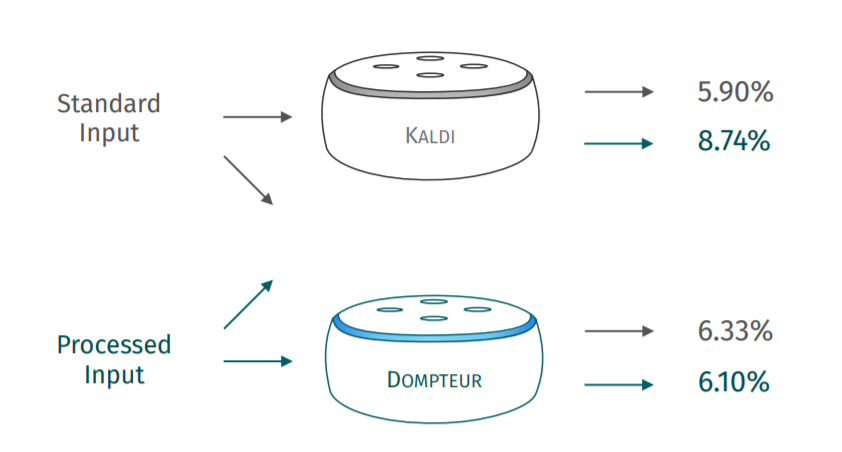

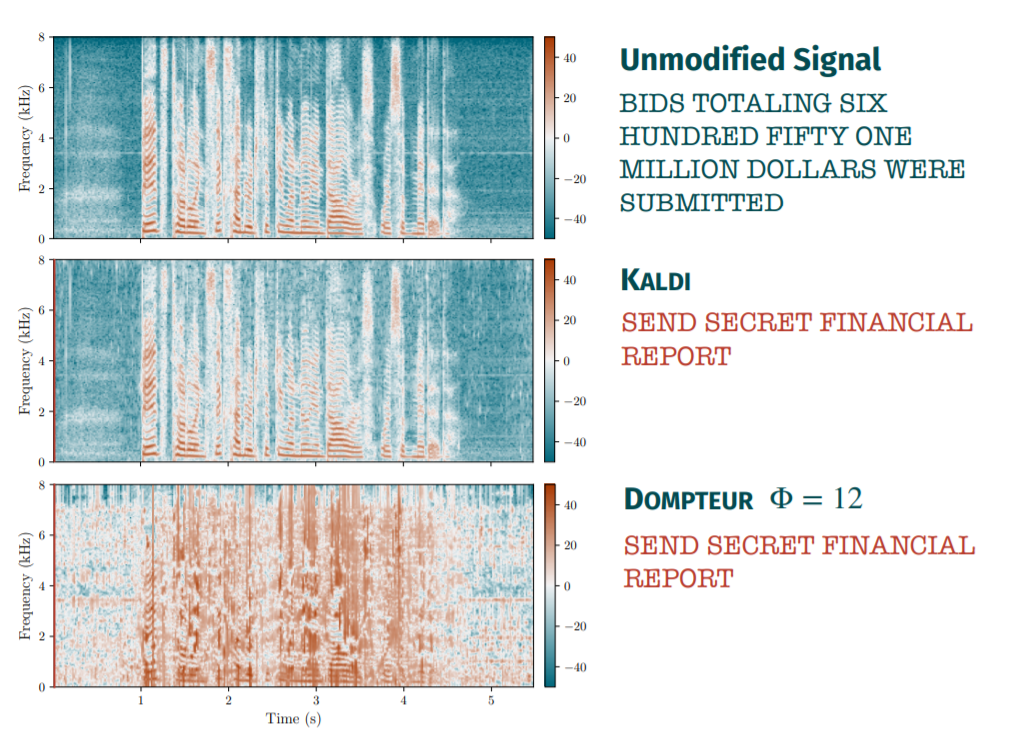
Problem
需要对现有的ASR基础上加入两个filter再重新训练才能维持对benign input的识别效果,如果对原始KALDI ASR输入processed input会导致benign input performance有一定的下降(因为原始ASR利用了inaudible information in signal)
转移到speaker recognition中是否对speaker recognition system performance有较大影响?
没有考虑black-box attack